
From Drift to Control: Building a Continuous Evaluation Pipeline for AI Agents
Date
June 25th, 2026
Reading Time
7 mins
AI agent failures often arrive quietly. One week, the agent handles customer questions with confidence and accuracy. The next, its answers become slightly less grounded, its tool choices less consistent, or its tone less aligned with the product experience. Nothing necessarily crashes, and no dashboard turns red. Instead, the system keeps running while its quality slips in ways that are hard to notice until users start feeling the impact.
Traditional software teams have a well-understood response to this problem. When code changes, continuous integration (CI) catches regressions before they reach production. CI is the practice of automatically testing and validating code changes before they are merged or released. But AI agents are not deterministic software components. They generate natural language, make probabilistic decisions, call tools dynamically, and adapt their behavior based on context. A simple unit test cannot tell whether an answer is faithful, safe, helpful, or merely worded differently.
To scale AI agents safely, teams need a new engineering discipline: Continuous Evaluation. If CI asks, “Does the code still work?”, Continuous Evaluation asks, “Does the agent still behave reliably, correctly, and safely under real-world conditions?”
Read more: OpenAI Agents SDK and The Future of Action-Oriented AI in Business
Why AI Agents Need More Than Traditional CI
Traditional CI works because most software is deterministic. If a function receives the same input, it should return the same output. A unit test can assert that 1 + 1 equals 2, or that an API returns a specific status code. The test either passes or fails.
AI agents operate differently. The same user query may produce two valid answers with different wording. A support agent may choose different but acceptable tool-call sequences. A research agent may summarize the same evidence in multiple ways. Exact-match assertions are too brittle for this world: they can flag correct answers as failures while missing subtle hallucinations that sound polished and confident.
This is why many teams fall back on “vibe-checking.” Before a release, someone manually tests a few prompts, scans the responses, and decides whether the agent “feels” good enough. That may work for a prototype. It collapses in production, where agents face thousands of inputs, edge cases, adversarial prompts, changing data, and model updates outside the team’s direct control.
The core problem is not that AI agents cannot be tested. It is that they require tests built for probabilistic behavior. Instead of asking whether an output matches one fixed string, teams must evaluate whether the output satisfies defined quality criteria.
The Two Core Pillars of Continuous Evaluation
A practical Continuous Evaluation pipeline rests on two foundations: a high-quality test dataset and an automated scoring mechanism. Together, they allow teams to move from subjective manual reviews to repeatable evaluation gates.
1. Golden Datasets
A golden dataset is a curated test suite that represents the most important scenarios your agent must handle. It typically contains input prompts, expected context, ideal outputs, acceptance criteria, and edge cases. For a customer support agent, this might include refund requests, policy exceptions, angry users, ambiguous questions, and prompt injection attempts. For an enterprise knowledge agent, it may include factual questions, multi-hop reasoning tasks, stale-document traps, and compliance-sensitive queries.
The best golden datasets are built from real failure modes. Start with production logs, support tickets, human review notes, and user feedback. Then enrich the dataset with synthetic cases generated by strong frontier models to simulate rare but high-risk interactions. The goal is not to test every possible prompt. The goal is to test the prompts that matter most: the ones that are common, costly, risky, or easy for the agent to mishandle.
2. LLM-as-a-Judge
Because AI agent outputs are often open-ended, hard-coded assertions are not enough. LLM-as-a-Judge uses a capable model to grade outputs against explicit rubrics. Instead of asking whether the response exactly matches a reference answer, the judge evaluates whether it meets quality criteria.
-
Faithfulness: Does the answer stay grounded in the provided context, or does it introduce unsupported claims?
-
Answer relevance: Does the response address the user’s actual intent?
-
Task completion: Did the agent complete the requested workflow or stop too early?
-
Tool-use correctness: Did the agent call the right tools with the right parameters?
-
Safety and guardrails: Did the agent resist prompt injection, avoid leaking system instructions, and stay within policy boundaries?
This does not mean blindly trusting another model. A robust judge should use clear scoring rubrics, stable examples, threshold bands, and periodic human calibration. The judge model should also be versioned or pinned where possible, so evaluation changes do not become another source of hidden drift.
Read more: The end of LLM dominance? A new path to AGI
Step-by-Step: The AI Agent CE Pipeline Workflow
A Continuous Evaluation pipeline should feel familiar to any engineering team already using CI/CD. CD refers to continuous deployment, which is the practice of automatically releasing validated changes to users or production environments. The difference is that the pipeline evaluates behavior, not just code correctness.
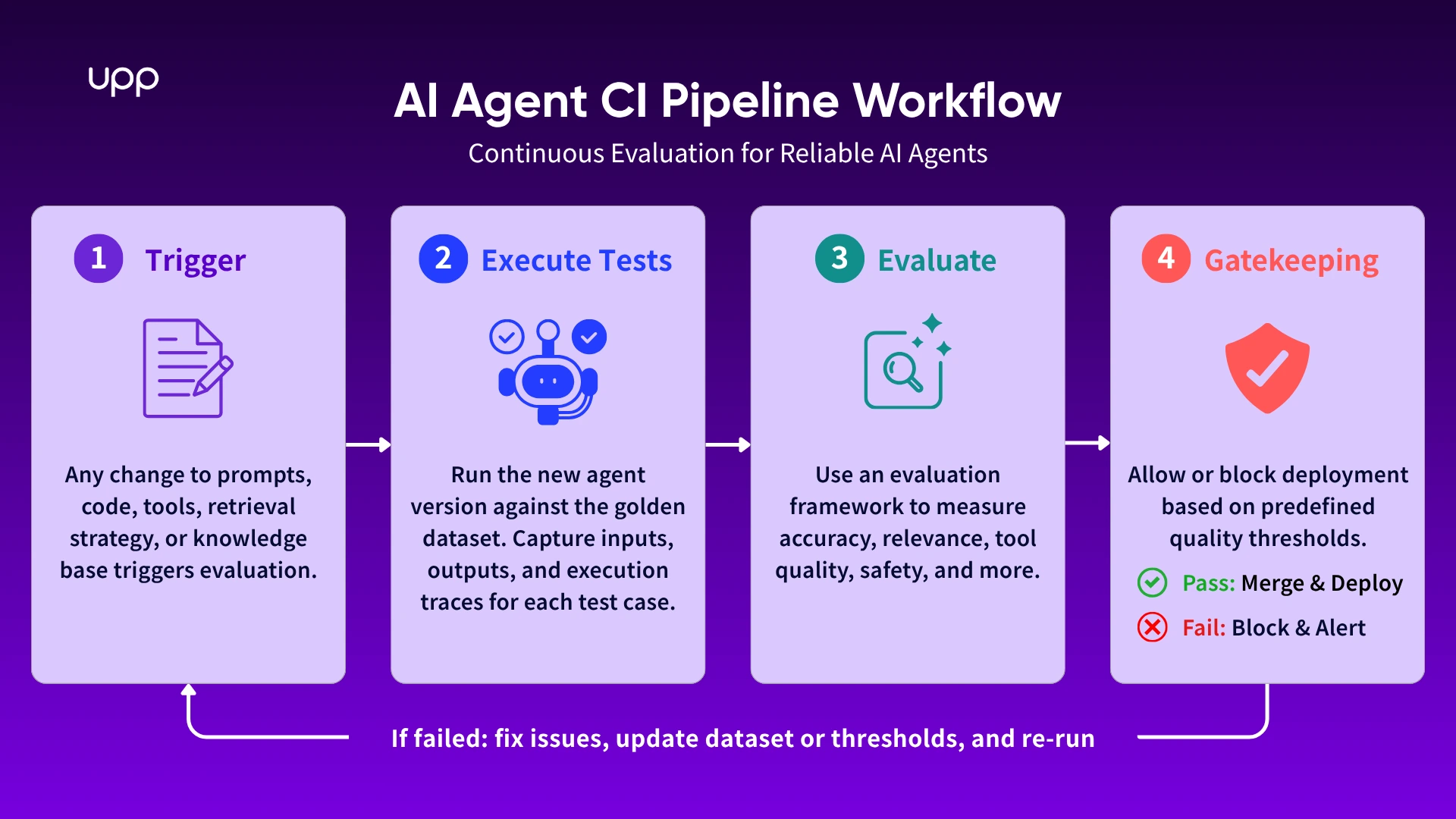
Step 1: Trigger
The process starts when something changes: a developer edits the system prompt, updates the agent code, changes the retrieval strategy, modifies the tool schema or refreshes the knowledge base. Any of these changes can alter agent behavior, so each should trigger evaluation before deployment.
Step 2: Execute Tests
The CI pipeline spins up the new agent version and runs it against the golden dataset. Each test case should capture not only the final response, but also the intermediate trace: retrieved documents, tool calls, reasoning steps where available, latency, token usage, and any policy flags.
Step 3: Evaluate
Evaluation frameworks such as Ragas, DeepEval, TruLens, LangSmith, Promptfoo, and MLflow can help score agent behavior across dimensions like faithfulness, relevance, hallucination risk, tool-use quality, and conversation-level performance. Ragas is often used for RAG-specific evaluation, DeepEval is popular for developer-friendly CI-style tests, TruLens combines evaluation with tracing, and LangSmith is commonly used in LangChain or LangGraph-based applications.
The key is to avoid relying on a single aggregate score. A passing average can hide a critical safety failure. Mature pipelines evaluate multiple dimensions separately and report regressions by category.
Step 4: Gatekeeping
Finally, the pipeline compares results against predefined thresholds. For example, the team may require faithfulness above 0.85, answer relevance above 0.80, tool-use correctness above 0.90, and zero critical safety violations. If the new version passes, the change can merge. If scores drop below the threshold, the pipeline blocks deployment and alerts the team.
Because LLM outputs are probabilistic, thresholds should be designed carefully. Use tolerance bands, stable test samples, and trend-based comparisons instead of treating every small score fluctuation as a hard failure. The purpose is to catch meaningful regressions, not to make the pipeline flaky.
Continuous Evaluation Meets AgentOps
Continuous Evaluation and AgentOps are closely related, but they are not the same thing. Continuous Evaluation tests the agent in the lab before release. AgentOps monitors the agent in the wild after release.
Continuous Evaluation answers pre-production questions: Did this prompt change reduce hallucinations? Did the new retrieval strategy improve relevance? Did the agent preserve compliance behavior after the latest model update? AgentOps answers production questions: What is the agent doing with real users? Where are failures happening? Which conversations are being downvoted? Which tool calls are timing out? Where are costs or latency spiking?
The most powerful setup connects the two into a feedback loop. When AgentOps detects an anomaly, a user downvote, a hallucination, or a failed workflow in production, that case should be isolated, reviewed, and added back into the golden dataset. The next time a developer changes the agent, the CI pipeline tests against that failure case automatically.
This is how teams turn production incidents into permanent safeguards. The agent does not just recover from mistakes; the evaluation system learns from them. Over time, the golden dataset becomes a living memory of the risks the agent has already encountered.
To dive deeper into how to set up real-time monitoring, tracing, and observability for production agents, connect this article to your AgentOps guide as the next step in the reliability journey.
Practical Takeaways for Engineering Teams
-
Treat prompts like code. Version them, review them, test them, and block unsafe changes before release.
-
Start with a small golden dataset. A focused set of 50 high-risk test cases is more useful than hundreds of vague prompts.
-
Evaluate multiple dimensions. Track faithfulness, relevance, tool use, safety, latency, and cost separately.
-
Use LLM judges carefully. Define rubrics, pin judge versions where possible, and calibrate with human review.
-
Close the loop with AgentOps. Convert production failures into new evaluation cases so the same issue does not recur silently.
Conclusion: Reliability Is an Engineering System
Making AI agents reliable over time is not a matter of luck. It requires bringing the rigorous engineering discipline of traditional CI/CD into the probabilistic world of AI. Continuous Evaluation doesn't replace the release guardrails software engineers have spent decades building, it completes them for the AI era.
The shift is simple but profound. Do not ask whether the demo still looks good. Ask whether the agent still meets defined standards across the scenarios that matter most. Do not rely on manual vibe checks. Build a pipeline that evaluates every meaningful change. Do not let production failures disappear into logs. Feed them back into the golden dataset.
From drift to control, this is how AI agents become production systems rather than prototypes.
How is your team currently testing AI agents before production? Share your approach in the comments, and stay tuned for the next piece on safe strategies for AI agents.
FAQ
What is Continuous Evaluation for AI agents?
Continuous Evaluation is the practice of automatically testing and measuring AI agent behavior whenever meaningful changes occur. Unlike traditional software testing, it focuses on behavioral quality metrics such as faithfulness, relevance, tool-use correctness, task completion, and safety rather than simple pass-or-fail outputs.
What is a golden dataset?
A golden dataset is a curated collection of test cases representing the most important scenarios an AI agent must handle. It typically includes common user requests, edge cases, historical failures, safety challenges, and high-risk workflows. Golden datasets serve as the foundation for repeatable and reliable agent evaluation.
What is LLM-as-a-Judge?
LLM-as-a-Judge is an evaluation approach where a capable language model assesses another model's output against predefined criteria. Instead of checking for exact answers, the judge evaluates dimensions such as factual accuracy, relevance, faithfulness, task completion, and safety using structured scoring rubrics.
Does Continuous Evaluation replace our existing CI/CD pipelines?
No, it extends them. Traditional CI/CD remains critical for checking deterministic logic, backend stability, API response times, and standard code regressions. Continuous Evaluation is simply an added layer within that exact pipeline that tests the probabilistic side of your application, ensuring that your agent’s prompts, reasoning steps, and outputs remain accurate and safe. Think of it as a specialized test suite running alongside your standard unit tests.
Does Continuous Evaluation replace human review?
No. Continuous Evaluation reduces the amount of manual testing required, but human oversight remains important. Teams should periodically review evaluation results, calibrate scoring rubrics, and audit critical workflows to ensure automated judges remain aligned with business and safety requirements.
What is the relationship between Continuous Evaluation and AgentOps?
Continuous Evaluation focuses on validating AI agents before deployment, while AgentOps focuses on monitoring and optimizing agents after deployment. Together they create a feedback loop: production failures detected through AgentOps can be added to the golden dataset and automatically tested in future releases.
Newsletter
DISCOVER MORE















































































![[Recap] UPP Global Technology JSC Establishing Anniversary](/homepage/news-section/new-4.webp)




















































LET’S TALK...
Content delivered to your inbox






ENTER YOUR EMAIL
YOU WANT TO...



Hanoi, Vietnam
Web3 Tower, No. 15, Alley 4, Duy Tan, Cau Giay, Hanoi, Vietnam