
UPP News: What's new in the AI field? (Part 5)
Date
February 23rd, 2024
Reading Time
5 mins
Tags cloud
What's news
Subscribe to our newsletter and stay up-to-date with the latest AI news updates.
1. Google introduces two new smaller open-source AI models
Source: The Verge
Just a week following the rollout of its latest Gemini models, Google has unveiled Gemma, a fresh lineup of lightweight open-weight models. Starting with Gemma 2B and Gemma 7B, these new models draw inspiration from Gemini and cater to both commercial and research needs.
While Gemini is a big closed AI model that is in direct competition with OpenAI’s ChatGPT, the lightweight Gemma is an open model that will likely be suitable for smaller tasks like chatbots and summarizations.
Despite their smaller stature, Google asserts that Gemma models outperform some larger models on key benchmarks and can operate directly on a developer's laptop or desktop. They'll be accessible through platforms like Kaggle, Hugging Face, Nvidia’s NeMo, and Google’s Vertex AI. The Goole DeepMind's product management director says the generation quality has improved significantly in the last year, making things that once required extensive models are now achievable with state-of-the-art smaller models.
Both sizes of Gemma models will be available with commercial licensing, regardless of organization size or project scope. However, Google maintains restrictions on using its models for questionable purposes. Gemma will also come equipped with responsible AI toolkits, recognizing that open models may pose challenges in implementing safeguards compared to more closed systems.
Gemma is accessible to ready-to-use Colab and Kaggle notebooks, along with integrations with Hugging Face, MaxText, and Nvidia’s NeMo. Once pre-trained and tuned, these models can then run everywhere. The models work best for language-related tasks in English for now.
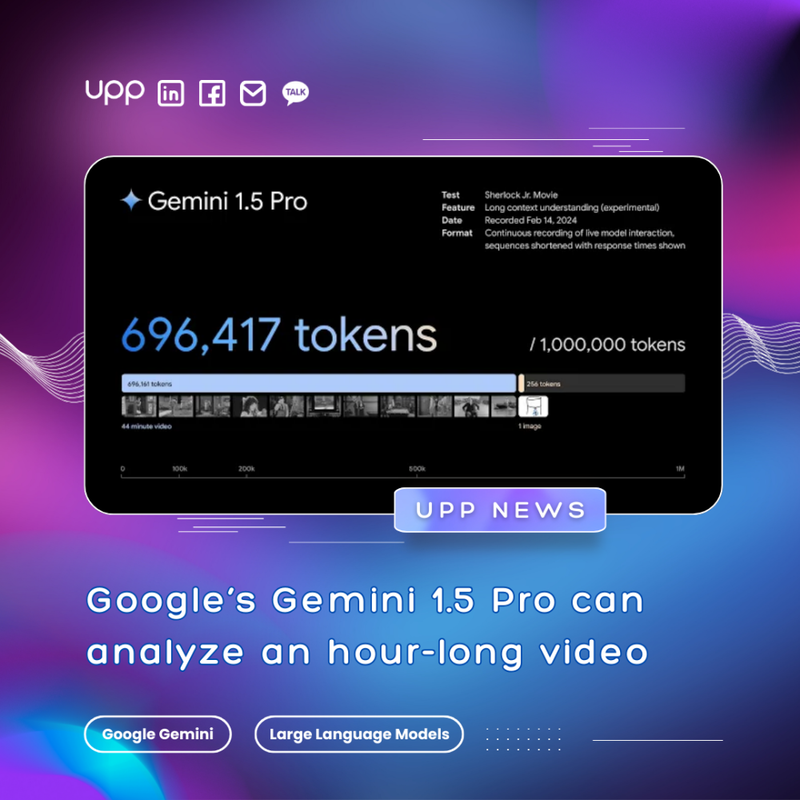
2. Google’s new Gemini model can analyze an hour-long video.
Source: TechCrunch, The Verge
Google has announced the release of Gemini 1.5 Pro, the newest member of its Gemini family of GenAI models and made it available to developers and enterprise users ahead of a full consumer rollout coming soon.
Gemini 1.5 Pro’s maximum context window is 1 million tokens, and the version of the model more widely available has a 128,000-token context window, the same as OpenAI’s GPT-4 Turbo. Tokens are a tricky metric to understand, but essentially, the more tokens a model has, the more accurate responses it can produce.
With such a quantity of context window tokens, the modal is promised to handle much longer queries and look at more information at once, thereby performing various tasks like reading lengthy documents like contracts, holding long conversations and analyzing content in videos. The multimodal model is not limited to text. Gemini 1.5 Pro can ingest up to 11 hours of audio or an hour of video in a variety of different languages.
For now, Gemini 1.5 will only be available to business users and developers, through Google’s Vertex AI and AI Studio. Eventually, it will replace Gemini 1.0, and the standard version of Gemini Pro will be 1.5 Pro with a 128,000-token context window. Users will have to pay extra to get to the million. Google is also testing the model’s safety and ethical boundaries, particularly regarding the newly larger context window.
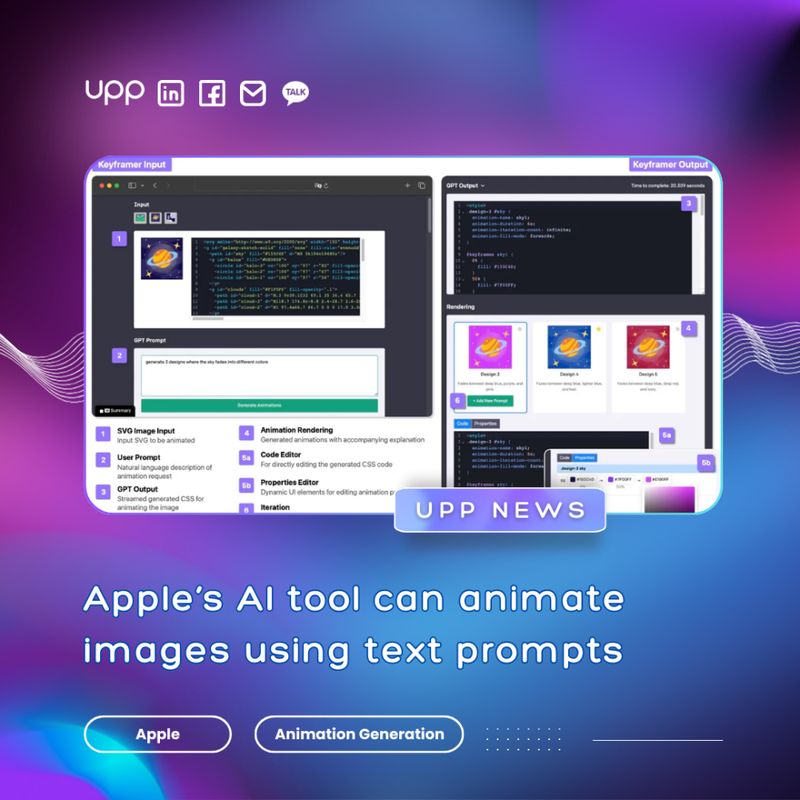
3. Apple’s AI tool can animate images using text descriptions.
Source: The Verge
Researchers at Apple have introduced Keyframer, a prototype generative AI animation tool that enables users to add motion to 2D images by describing how they should be animated.
Using OpenAI’s GPT4 as its base model, Keyframer can take Scalable Vector Graphic (SVG) files — an illustration format that can be resized without interfering with quality — and generate CSS code to animate the image based on a text prompt. You just upload the image, type something like “make the stars twinkle,” in the prompt box, and hit generate.
Users can produce multiple animation designs in a single batch, and adjust properties like color codes and animation durations in a separate window. No coding experience is necessary as Keyframer automatically converts these changes into CSS, though the code itself is also fully editable. This description-based approach is much simpler than other forms of AI-generated animation, which typically requires several different applications and some coding experience.
Still, it has a long way to go. Keyframer has not been publicly available yet and the company was careful to mention its limitations, specifying that Keyframer focuses on web-based animations like loading sequences, data visualization, and animated transitions. By contrast, the kind of animation often seen in movies and video games is far too complex to produce using descriptions alone.
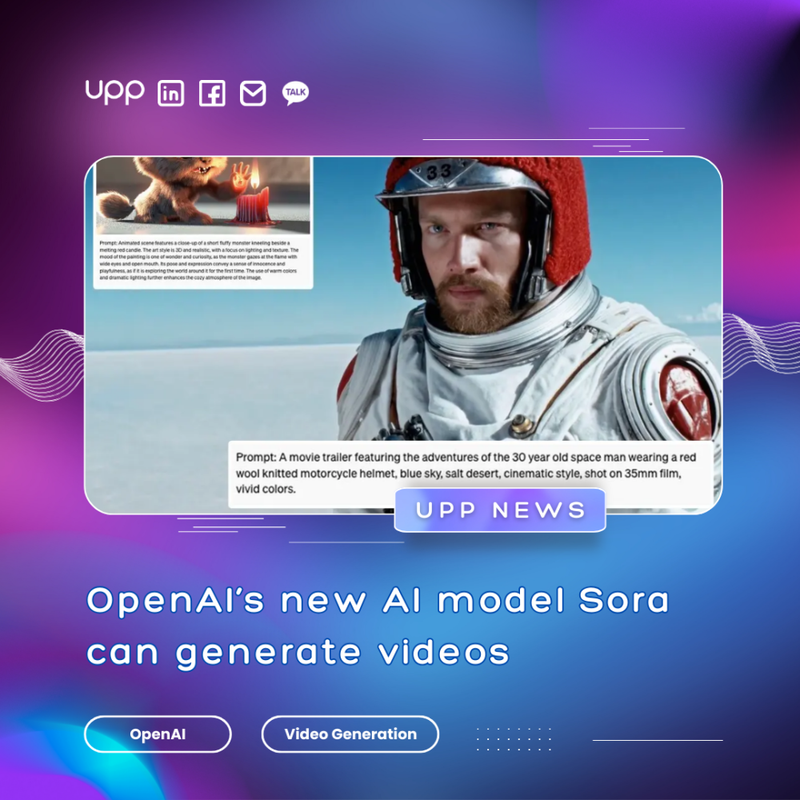
4. OpenAI’s new AI model Sora can generate videos.
Source: TechCrunch
OpenAI has introduced Sora, a generative AI model designed to turn text into video content. With Sora, users can provide either a brief or detailed description, or even a still image, and the model with produce stunning movie-like scenes with various characters, diverse motions, and background details.
Sora has a profound understanding of language, allowing it to accurately interpret prompts and create captivating characters that express vibrant emotions.
One of Sora's remarkable features is its ability to produce videos in diverse styles, such as photorealistic, animated with durations of up to a minute—considerably longer than many other text-to-video models. Moreover, these videos maintain a sense of coherence, minimizing unnatural movements like objects moving in physically impossible directions.
Despite its advancements, OpenAI acknowledges that Sora isn't flawless. The model may encounter challenges in accurately simulating the physics of complex scenes and may overlook specific cause-and-effect relationships.
In light of these limitations, OpenAI will continue to refine Sora and its capabilities and remains committed to fostering responsible and ethical use of AI in collaboration with stakeholders.
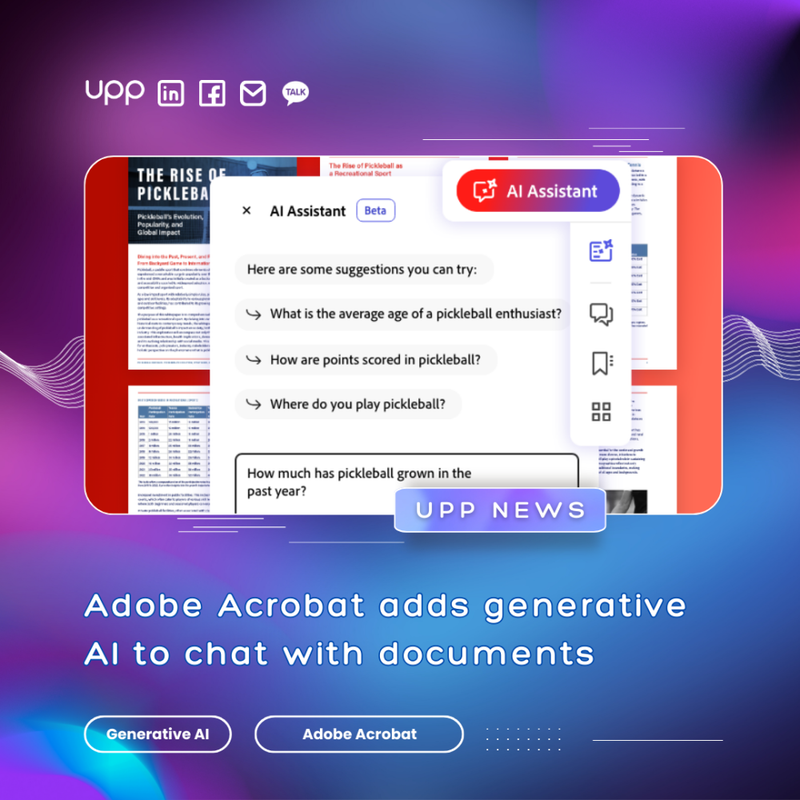
5. Adobe Acrobat adds generative AI to chat with documents.
Source: The Verge
Adobe is introducing an exciting new AI experience to its Acrobat PDF management software, aiming to make navigating and understanding lengthy documents a breeze.
Called the "AI Assistant in Acrobat," this handy tool acts like a friendly conversational chatbot, summarizing documents, answering questions, and even suggesting related content to help users easily find the information they need. Starting today, it's available as a beta feature for paying Acrobat users.
The AI Assistant promises to simplify the often daunting task of working with large text documents. For students, it could mean quickly finding research material, while for professionals, it could mean summarizing hefty reports for emails, meetings, or presentations. The AI chatbot also works with all document formats supported by Acrobat, including Word and PowerPoint.
Interested in AI Implementation for your business? Let us reach you !
Tags cloud
Newsletter
DISCOVER MORE
















































































![[Recap] UPP Global Technology JSC Establishing Anniversary](/homepage/news-section/new-4.webp)



















































LET’S TALK...
Content delivered to your inbox






ENTER YOUR EMAIL
YOU WANT TO...



Hanoi, Vietnam
Web3 Tower, No. 15, Alley 4, Duy Tan, Cau Giay, Hanoi, Vietnam