
What's new in Mixture of Experts in 2025?
Date
July 23rd, 2025
Reading Time
7 mins
What's news
Introduction
As the scale and complexity of AI models continue to grow in 2025, Mixture of Experts (MoE) remains at the forefront of innovation, driving performance while optimizing computational efficiency.
Since our last deep dive into MoE, the landscape has changed significantly. Emerging innovations in routing mechanisms and architectural design have enabled MoE models to redefine the capabilities of large-scale AI systems.
In this post, we'll explore the key innovations that have transformed MoE from a research concept into the production-ready architecture powering today's most advanced AI systems.
Read more: The History of Mixture of Experts
Why MoE?
The MoE architecture introduces sparsity in LLMs to address the challenges of Neural scaling laws, which state that model performance improves with more parameters, compute resources, and dataset size. While increasing model parameters is the simplest way to boost performance, larger models demand significantly more computing for training and inference, making them costly and inefficient. MoE tackles this by dividing the model into multiple "experts," where only a small subset is activated for any given input. This sparsity allows MoE to maintain a high parameter count for better performance while drastically reducing computational requirements compared to a dense model of the same size.
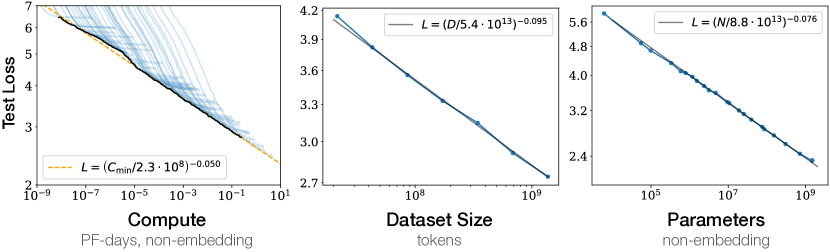
Source: Scaling Laws for Neural Language Models
1. Gating function
In a standard transformer architecture, each layer typically includes a multi-head self-attention mechanism followed by a Feed-Forward Network (FFN) layer. In a MoE architecture, the FFN layer is replaced by a MoE layer, which consists of a Gating layer and multiple Expert layers.
The output of an MoE layer for an input x is given by the formula:
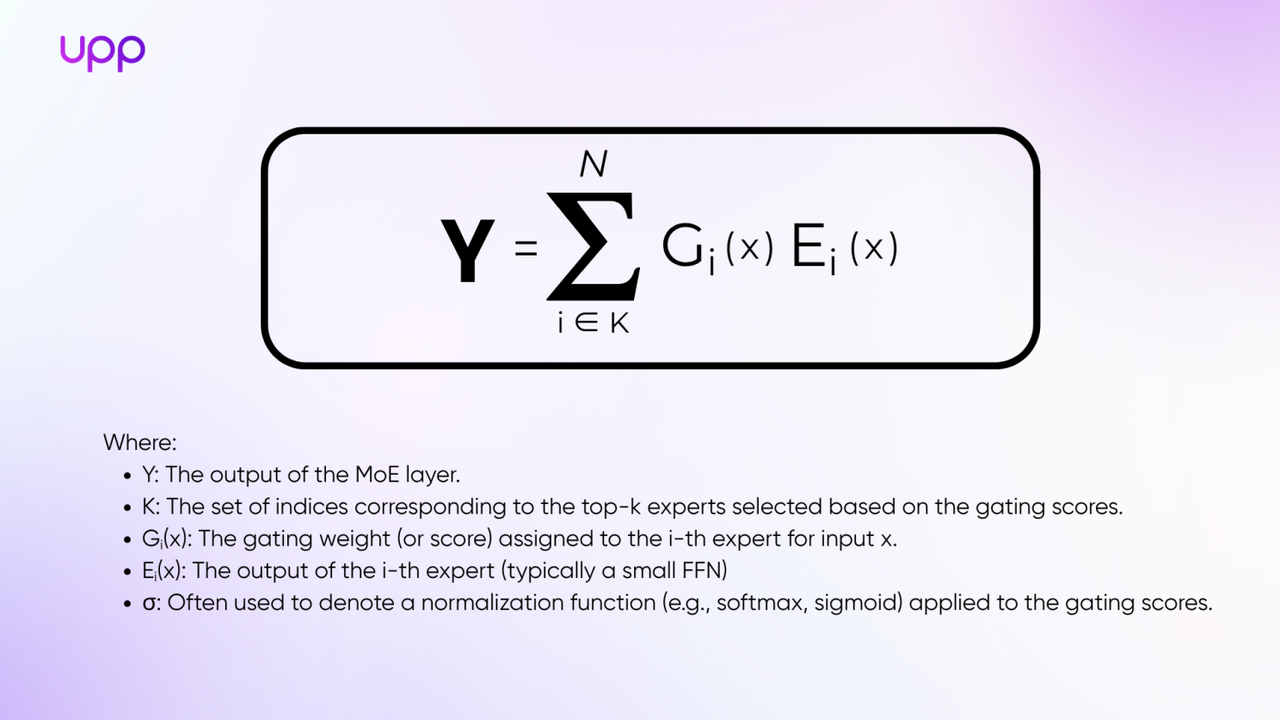
2. Load balancing
If all the tokens are focused on just a subset of experts, it makes the model inefficient. Therefore, we use auxiliary loss to encourage the model to select a wide range of experts instead of converging in just a few one.

The function penalty only a subset of Experts is selected (high f, P), and encourage the choice spread evenly between experts.
MoE in 2025
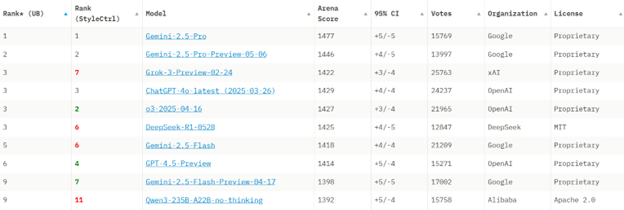
MoE architecture is still proven to have top performance in 2025. Two of the highest ranking open-source models (up to July 2025) are MoE models (DeepSeek-R1 and Qwen3 235B A22B)
1. Change in Gating Function
Previously, the go-to choice for gating function is softmax. However, due to the exponential of softmax function, it makes the choice of expert more competitive, which leads to unstable training. Current design adopts another choice of using sigmoid to reduce the competition between experts, with the most popular example is DeepSeek V3 and DeepSeek R1. However, there is no “one-size-fit-all" model design, and the choice often varies depending on specific needs or design preferences.
2. Change in number of experts
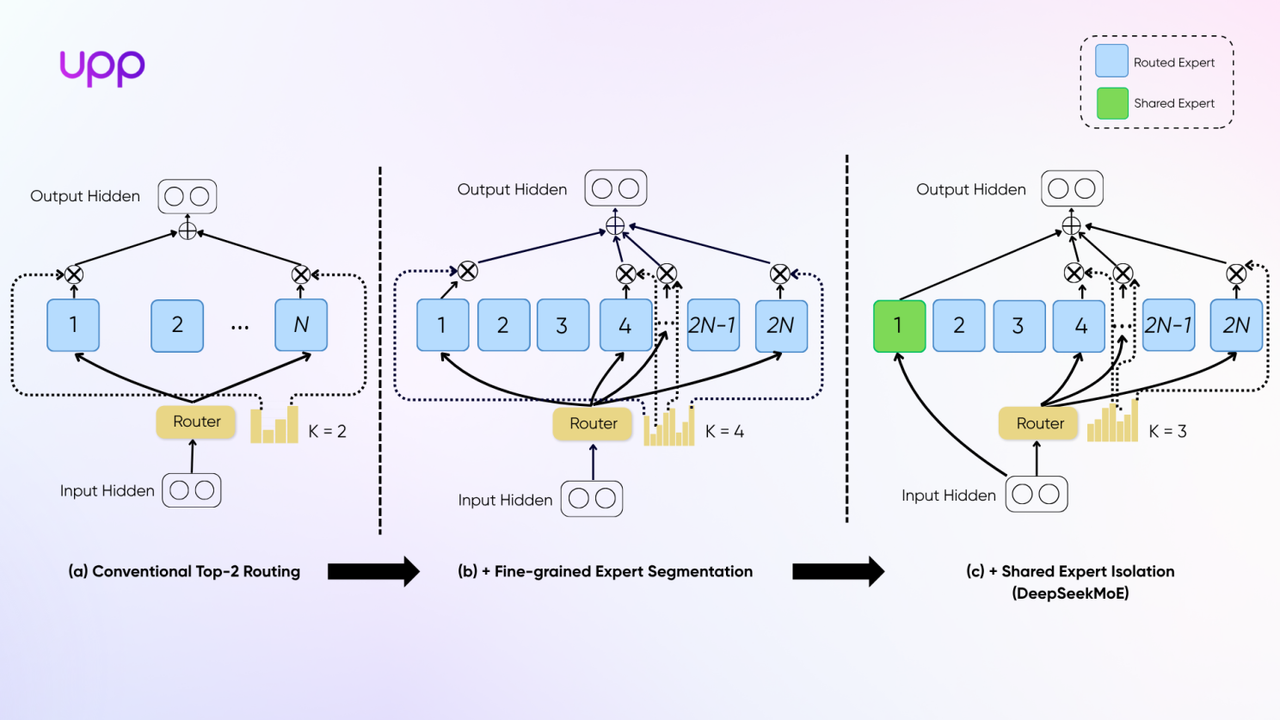
The number of experts in MoE models has seen a significant increase, moving away from the previous standard of 8 experts with 2 active per token. This scaling is driven by the need for finer-grained specialization and improved model capacity, starting with the improvement of DeepSeekMoE (cite):
-
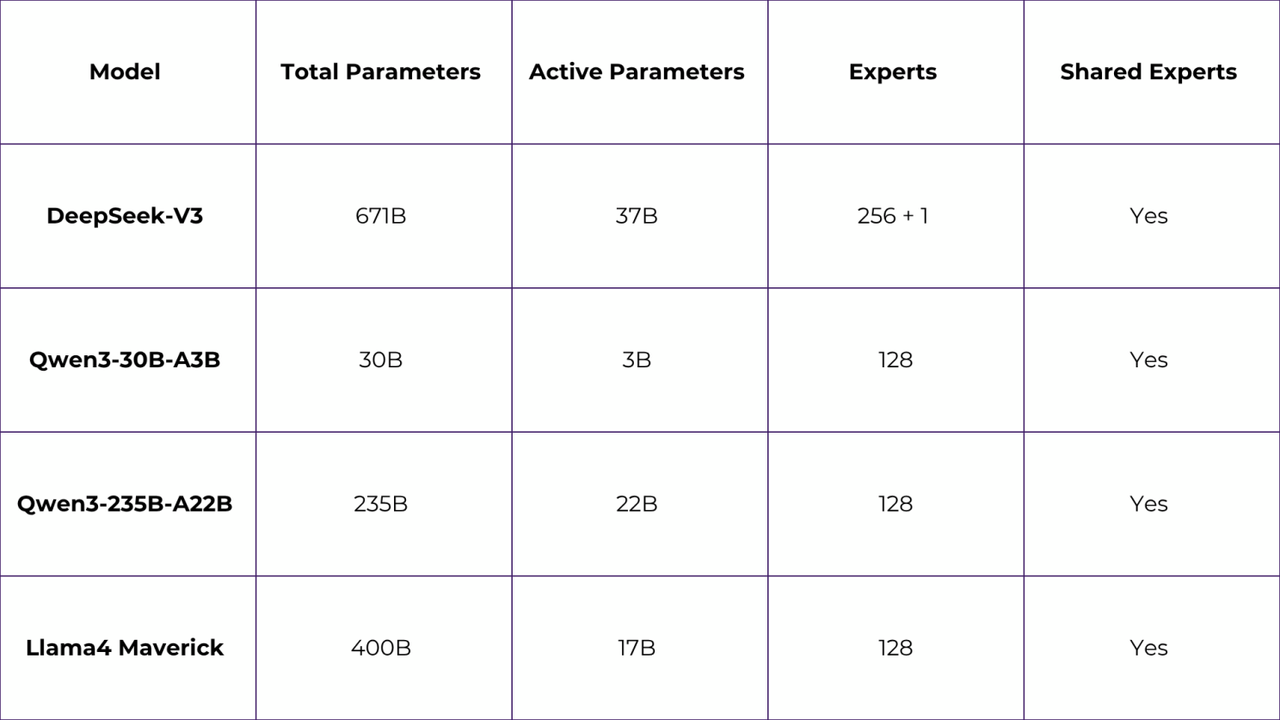
Fine-Grained Expert Segmentation reduced the hidden layer in each Expert, scale to a larger number of experts. DeepSeek has 256 + 1 Experts, and Qwen3 and Llama4 Maverickhave 128.
-
Shared expertsare a novel approach to reduce parameter redundancy and enhance diversity among experts, addressing the issue where previous choices led to similar knowledge across experts. Shared experts encourage them to go into shared experts, making other experts more “diversity”. Since late 2024, all the MoE models employ shared experts in their architecture.
By using both technics, the model can still have the same high number of parameters while using less training and inference time, and the risk of overfitting is greatly reduced. This significantly enhances model performance, and as “thinking” models gain prominence, the capacity to store more “knowledge” is vital. MoE with shared experts has demonstrated its effectiveness, becoming the preferred approach for leading open-source reasoning models like DeepSeekR1, Qwen3, and Kimi2.
Here is the Comparative Analysis of the architecture of the common MoE models in 2025 in general tasks.
3. Improvement in Load Balancing
To balance between the model collapse from no load balancing and performance degradation, there have been multiple new approaches for this. DeepSeek uses Auxiliary-Loss-Free Load Balancing to balance the score of each model and includes additional sequence-wise auxiliary loss to prevent extreme balance between tokens in the sentence.
Conclusion
The evolution of Mixture of Experts in 2025 highlights the industry's shift toward smarter scaling: more experts, better diversity, and more stable training. With innovations like sigmoid-based gating, shared expert designs,fine-grained expert segmentation and auxiliary-loss-free load balancing, models such as DeepSeek-V3 and Qwen3 highlight how MoE has matured into a robust and flexible architecture. As we look ahead, MoE stands out as a cornerstone of next-gen AI architecture and these architectural innovations signal a future where AI systems can achieve unprecedented scale while maintaining efficiency, a crucial step toward more capable and accessible artificial intelligence.
Newsletter
DISCOVER MORE















































































![[Recap] UPP Global Technology JSC Establishing Anniversary](/homepage/news-section/new-4.webp)




















































LET’S TALK...
Content delivered to your inbox






ENTER YOUR EMAIL
YOU WANT TO...



Hanoi, Vietnam
Web3 Tower, No. 15, Alley 4, Duy Tan, Cau Giay, Hanoi, Vietnam