
The end of LLM dominance? A new path to AGI
Date
April 3rd, 2026
Reading Time
7 mins
What's news
Abstract
The current AI paradigm is dominated by large language models (LLMs), which scale performance through data, parameters, and compute. While effective for language tasks, this paradigm shows structural limitations in reasoning, consistency, and real-world interaction. Recent ideas from Yann LeCun and the startup Logical Intelligence propose a different direction based on energy-based models (EBMs), world models, and modular architectures. This article provides a technical deep dive into why autoregressive modeling may not be sufficient for AGI, how EBMs reframe inference as optimization, and how a hybrid AI stack could enable more robust, controllable, and generalizable intelligence systems.
Autoregressive scaling and its structural bottlenecks
Modern LLMs are autoregressive models that approximate the conditional distribution
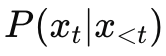
Training minimizes cross-entropy loss over large corpora, effectively compressing statistical regularities of language into a parametric model. This objective is extremely efficient for next-token prediction, but it introduces structural constraints that become visible in downstream reasoning tasks, there are also limitations of autoregressive models.
First, inference is inherently sequential. Each token depends on previously generated tokens, which creates exposure bias and error accumulation. Even with techniques like chain-of-thought prompting, the model does not truly “reason” but instead generates plausible reasoning traces. These traces are not guaranteed to be globally consistent because the optimization objective is local (token-level likelihood), not global (solution validity).
Second, LLMs lack an explicit mechanism for constraint satisfaction. Logical rules, physical laws, or system constraints are only implicitly encoded in weights. This leads to instability in tasks requiring strict adherence to rules, such as symbolic reasoning, planning, or program synthesis under constraints.
Third, scaling laws show diminishing returns. Increasing parameters improves perplexity, but improvements in reasoning accuracy are non-linear and often plateau. More importantly, compute cost grows superlinearly, making continued scaling economically and environmentally challenging.
From an engineering perspective, the key limitation is this: autoregressive models optimize for likelihood, not correctness. This mismatch becomes critical when moving from generative tasks to decision-making systems.
Read more: The Inevitable Obsolescence of Pure LLMs
Energy-based models as a unifying framework
Energy-based models (EBMs) provide a fundamentally different formulation, shows differences between probabilistic vs deterministic AI. Instead of modeling probability distributions explicitly, EBMs define an energy function over configurations and perform inference via optimization.
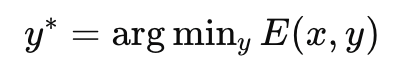
Here, E(x,y)E(x, y)E(x,y) is a learned compatibility function between input xxx and candidate solution yyy. Unlike autoregressive decoding, which constructs yyy incrementally, EBMs treat yyy as a whole object and search for a configuration that minimizes energy.
This shift has several deep implications.
First, EBMs decouple representation from inference. The model learns an energy landscape, while inference is performed via optimization methods such as gradient descent, Langevin dynamics, or combinatorial search. This allows the same model to support multiple inference strategies depending on the task.
Second, constraints can be explicitly encoded. Hard constraints can be added as penalty terms in the energy function, while soft constraints can be learned from data. This makes EBMs naturally suited for structured problems where validity conditions must be satisfied.
Third, EBMs support iterative refinement. Instead of committing to early decisions (as in autoregressive decoding), the system can continuously adjust the solution. This enables self-correction and reduces error propagation.
From a systems perspective, EBMs shift computation from generation-heavy pipelines to optimization-heavy pipelines, which can be more efficient for high-precision tasks.
Inference as optimization vs. sampling

A critical engineering distinction between LLMs and EBMs lies in inference.
LLMs rely on sampling-based decoding strategies such as greedy search, beam search, or nucleus sampling. These methods approximate the most likely sequence but do not guarantee constraint satisfaction. Increasing beam width improves exploration but increases compute cost significantly.
EBMs, on the other hand, perform inference by directly optimizing the objective function. This allows the system to incorporate global information at every step. For example, in a planning task, constraints such as resource limits, temporal dependencies, and safety conditions can all be evaluated simultaneously during optimization.
This difference becomes especially important in combinatorial spaces. In such spaces, the number of possible solutions grows exponentially, making sequential generation inefficient. Optimization-based approaches can exploit structure to converge faster.
However, EBMs introduce their own challenges. The energy landscape may be non-convex, leading to local minima. Designing efficient optimization procedures is therefore critical. In practice, hybrid AI architecture may be used, where neural networks guide the search process.
Constraint satisfaction and compositional generalization
One of the strongest motivations behind EBMs is their ability to handle constraint satisfaction problems. These problems require the model to produce outputs that satisfy multiple interacting conditions.
In LLMs, constraints are enforced indirectly through prompting or fine-tuning. This is brittle and does not scale well. In contrast, EBMs can integrate constraints directly into the objective function. This enables more reliable solutions and better compositional generalization.
Compositional generalization refers to the ability to combine known concepts in new ways. LLMs often struggle with this because they rely on pattern matching rather than rule-based reasoning. EBMs, by operating on structured representations and constraints, are better positioned to generalize across combinations.
From an engineering standpoint, this is critical for domains like:
-
Scheduling systems with multiple constraints
-
Robotics planning with physical limitations
-
Scientific modeling with known equations
In these domains, correctness is not optional. A single violation can invalidate the entire solution.
World models and latent dynamics
A core argument from Yann LeCun is that intelligence requires models of the world, not just models of language. World models aim to learn latent representations of environment dynamics.
Technically, a world model can be viewed as learning a transition function in latent space:
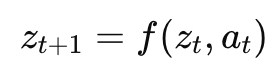
where ztz_tzt is the latent state and ata_tat is an action. The model learns to predict future states given current states and actions. This enables planning through simulation.
Unlike LLMs, which operate in token space, world models operate in state space. They are trained on sequences of observations (e.g., video frames) and learn temporal structure. This allows them to capture causality and physical interactions.
When combined with EBMs, world models can provide constraints derived from physics or environment dynamics. This creates a powerful loop: the world model predicts outcomes, and the EBM evaluates candidate plans based on constraints.
Toward a modular AGI system
The architecture proposed by Logical Intelligence is inherently modular. Instead of a single end-to-end model, the system consists of multiple interacting components.
In such a system, LLMs serve as the interface layer, translating between human language and internal representations. EBMs act as the reasoning layer, solving structured problems through optimization. World models provide grounding by simulating the environment.
This separation introduces several engineering advantages. Each module can be trained with different objectives and datasets. Updates can be applied locally without retraining the entire system. Failures can be isolated and debugged more easily.
More importantly, modularity allows for heterogeneous compute strategies. For example, LLM inference may run on GPUs optimized for dense matrix operations, while EBM optimization may leverage specialized solvers or even classical algorithms.
System-level challenges and open problems
Despite its promise, this approach introduces significant challenges.
One major issue is integration. Communication between modules requires well-defined interfaces and shared representations. Latency can become a bottleneck, especially when iterative optimization is involved.
Another challenge is training alignment. Each module may optimize a different objective, leading to potential conflicts. Ensuring that the system behaves coherently requires careful design of loss functions and interaction protocols.
Optimization in EBMs is also non-trivial. Poorly designed energy functions can lead to unstable behavior or slow convergence. Scaling EBMs to high-dimensional spaces remains an active research problem.
Finally, there is the question of data. While LLMs benefit from large-scale text corpora, world models require high-quality multimodal data, which is harder to collect and standardize.
Read more: What Data Pipelines do LLM systems actually need?
Conclusion
The dominance of LLMs is not ending immediately, but their role is being redefined. As highlighted by Yann LeCun and Logical Intelligence, the path to AGI may require a shift from pure autoregressive modeling to a more structured and modular approach.
From an engineering perspective, the key transition is from probabilistic generation to constraint-driven optimization, and from text-based learning to world-grounded modeling. This shift introduces new challenges, but it also opens the door to systems that are more reliable, interpretable, and capable of true reasoning.
If this direction succeeds, future AI systems will not just generate plausible outputs. They will compute solutions that are correct by design, grounded in reality, and adaptable across domains.
👉 Subscribe to our newsletter and get the latest AI news updates: https://lnkd.in/g28eg-iW
Newsletter
DISCOVER MORE















































































![[Recap] UPP Global Technology JSC Establishing Anniversary](/homepage/news-section/new-4.webp)




















































LET’S TALK...
Content delivered to your inbox






ENTER YOUR EMAIL
YOU WANT TO...



Hanoi, Vietnam
Web3 Tower, No. 15, Alley 4, Duy Tan, Cau Giay, Hanoi, Vietnam